




In the bustling streets of a metropolis, autonomous vehicles glide seamlessly through traffic, analyzing their surroundings, making split-second decisions, and ensuring a smooth and safe journey for passengers. Meanwhile, in research laboratories worldwide, medical experts use AI technology to diagnose complex diseases with unprecedented accuracy. Behind these remarkable feats lies the power of neural networks, an ingenious computational approach inspired by the human brain. As neural networks continue to shape the landscape of artificial intelligence, their transformative potential and ever-evolving capabilities have captivated researchers and innovators alike.
Neural networks have significantly evolved since their inception in 1958. What started as a simple concept inspired by the workings of the human brain has blossomed into a sophisticated and powerful computational framework. Over the years, researchers and scientists have made significant advancements in understanding and refining neural networks, unlocking their immense potential to positively impact various fields of artificial intelligence. Through continuous refinement, improved algorithms, and the advent of powerful computing resources, neural networks have grown in complexity and capability, enabling them to tackle increasingly complex tasks and achieve remarkably accurate results. Neural networks possess an impressive ability to process vast amounts of data, recognize intricate patterns, and make predictions with unprecedented accuracy. The impact of neural networks goes far beyond specific domains such as Natural Language Processing (NLP), image recognition, and autonomous vehicles. It has opened up new possibilities across a diverse range of fields and industries. These remarkable advancements have firmly established neural networks as a fundamental pillar driving the advancement of artificial intelligence as a whole.
In this article, we will take a deep dive into the intricacies of neural networks, exploring their architecture, working function, types, applications and more.
- What are neural networks?
- The architecture of neural networks
- The biological inspiration behind neural networks
- How do neural networks work? Understanding through an example
- Types of neural networks
- How to build and train a neural network?
- How to assess the performance of a neural network?
- Neural network vs. deep learning
- Practical applications of neural networks
- Real-world case studies of neural networks
What are neural networks?
Neural networks, also referred to as Artificial Neural Networks (ANNs), are computational models that draw inspiration from the structure and operations of the human brain. They comprise interconnected nodes, or artificial neurons, organized in layers. Neural networks are designed to process and examine complex data, recognize patterns, and make predictions or decisions based on their learned knowledge. They excel in solving problems that are difficult to define using traditional programming techniques or when explicit rules are unavailable.
The architecture of neural networks
The structure of a neural network comprises layers of interconnected nodes, commonly referred to as neurons or units. These neurons are organized into three main types of layers: an input layer, one or more hidden layers, and an output layer. Let us understand each key element of the neural network in detail:
- Input layer: The input layer is responsible for receiving the initial data or features that are fed into the neural network. Each neuron in the input layer depicts a specific feature or attribute of the input data.
- Hidden layers: Hidden layers are intermediate layers between the input and output layers. They perform complex computations and transformations on the input data. A neural network can have numerous hidden layers, each consisting of numerous neurons or nodes.
- Neurons (Nodes): Neurons or artificial neurons are fundamental units of a neural network. They receive input signals and perform computations to produce an output. Neurons in the hidden and output layers utilize activation functions to introduce non-linearities into the network, allowing it to learn complex patterns.
- Weights and biases: Weights and biases are adjustable parameters associated with the connections between neurons. Each connection has a weight, which determines the strength or importance of the input signal. Biases, on the other hand, provide an additional tunable parameter that allows neurons to adjust their activation threshold.
- Activation functions: Activation functions are threshold values that introduce non-linearities into the neural network, enabling it to comprehend complex relationships between inputs and outputs. Common activation functions include sigmoid, tanh, ReLU (Rectified Linear Unit), and softmax.

- Output layer: The output layer generates the final predictions or outputs of the neural network. The number of artificial neurons in the output layer depends on the specific problem being solved. For example, in a binary classification task, there may be one neuron representing each class (e.g., “yes” or “no”), while in multi-class classification, there will be multiple neurons representing each class.
- Loss function: The loss function measures the discrepancy between the predicted outputs of the neural network and the true values. It quantifies the network’s performance and guides the learning process by providing feedback on its performance.
- Backpropagation: Backpropagation is a learning algorithm used to train a neural network. It involves propagating the error (difference between predicted and actual outputs) backward through the network and adjusting the weights and biases iteratively to minimize the loss function.
- Optimization algorithm: Optimization algorithms, such as gradient descent, are employed to update the weights and biases during training. These algorithms determine the direction and magnitude of weight adjustments based on the gradients of the loss function concerning the network parameters.

The biological inspiration behind neural networks
The structure and functionality of neural networks are derived from biological neural networks, particularly those of the brain. The biological inspiration behind neural networks lies in understanding how neurons, the brain’s basic building blocks, work together to process and transmit information.
- Neurons: Neurons are specialized cells in the brain that receive, process, and transmit electrical and chemical signals. They are interconnected through synapses, which are the points of communication between neurons.
- Neural connections: Neurons are connected to each other in intricate networks, forming complex pathways for information flow. These connections allow neurons to communicate and transmit signals throughout the brain.
- Activation and signaling: When a neuron receives input signals from other neurons, it integrates them and generates an output signal. This output signal, often called the neuron’s activation, is transmitted through the neuron’s axon to other connected neurons via synapses.
- Learning and adaptation: The strength of connections between neurons can change over time through a process called synaptic plasticity. This ability to adapt and modify the strength of connections based on experience is crucial for learning and memory formation in the brain.
- Hierarchical organization: The brain exhibits a hierarchical organization, with simpler processing occurring at lower levels and more complex processing occurring at higher levels. This hierarchical arrangement allows for the gradual abstraction and representation of information.
Artificial neural networks attempt to emulate these biological principles in artificial systems. They consist of artificial neurons, also known as units or nodes, which are interconnected through weighted connections, simulating the synapses of biological neurons. The weights of these connections are tuned during training to optimize the network’s performance on specific tasks.
The layered structure of neural networks, with input, hidden, and output layers, reflects the hierarchical organization of the brain. Information flows through the network, with each layer processing and transforming the input data until it reaches the output layer, producing the network’s prediction or decision.
While artificial neural networks are simplified abstractions of the brain, they capture essential principles of information processing and learning from biological neural networks. By emulating the behavior of neurons and their interconnections, neural networks can learn from data, recognize patterns, and make intelligent decisions, contributing to the field of artificial intelligence.
How do neural networks work? Understanding through an example
Let us understand the working function of neural networks through an example. For that, we will consider a neural network that can distinguish between a circle, triangle and square.
1. Data preparation
First, we need a labeled dataset containing images of circles, squares, and triangles. Each image should be labeled with its corresponding shape. It’s important to have a diverse and representative dataset to train the neural network effectively.
2. Network architecture
We design our neural network’s architecture based on the task’s complexity. We can use a neural network with multiple hidden layers in this case. The input layer will take in the image data, and the output layer will have three neurons, each representing one shape (circle, square, or triangle).
3. Input representation
Next, we need to convert the shape images into a suitable format to create the input for the neural network. This can be achieved by representing each image as a flattened array of pixel values or by utilizing more advanced techniques, such as Convolutional Neural Networks (CNNs) that can directly process image data. In this case, the choice would be pixelated representation of the image.
4. Activation function and forward propagation
Let’s consider a scenario with a circular image composed of 30 by 30 pixels, totaling 900 pixels. Each pixel is fed as input to each neuron (represented as x1, x2, which goes until x900) of the first layer/input layer. Neurons of one layer are connected to neurons of the next layer through channels, and each channel is assigned a numerical value known as weight (e.g., 0.8, 0.2, etc.).
The input values (pixels) are multiplied by the corresponding weights, and their sum is sent as input to the neurons in the hidden layers. Each neuron in the hidden layers also has a numerical value called the bias (e.g., B1 , B2 , etc.). The bias is added to the input sum, and the resulting value is passed through a threshold function called the activation function. The activation function determines whether the particular neuron will be activated or not.
The activated neurons transmit data to the neurons in the next layer through the channels, propagating the data through the network. This process is known as forward propagation.
The neuron with the highest value is activated in the output layer and determines the final output. The values in the output layer represent probabilities. To obtain these probabilities, we commonly use the SoftMax activation function. Softmax takes a vector of real numbers as input and transforms them into a probability distribution over multiple classes, ensuring that they sum up to 1. This allows us to interpret the neural network output as the predicted probabilities for each class of shapes, such as circles, squares, or triangles.
Launch your project with LeewayHertz
We build robust AI-powered solutions tailored to your needs
5. Loss function
In the output layer, if the neuron associated with the square receives the highest probability, it will be considered the predicted output. However, if the input image were actually a circle, the neural network’s prediction would be incorrect. So, how does the neural network discover if its predictions are right or wrong? The loss function helps the neural network to calculate how well the model has performed on the task at hand.
A loss function, alternatively known as an objective function or a cost function, is a mathematical function that measures the discrepancy between the predicted output of a machine learning model and the true or desired output. It quantifies how much the model’s predictions deviate from the actual values. We need a suitable loss function to train the neural network that quantifies the difference between the predicted probabilities and the true labels.
6. Backpropagation and optimization
Backpropagation, short for “backward propagation of errors,” is a fundamental algorithm used in training neural networks. It enables the network to learn from its mistakes and adjust its internal parameters (weights and biases) to improve its predictions.
In backward propagation, the network compares the predicted output with the true output and calculates the gradient of the loss function concerning the network’s parameters. This gradient indicates the direction and magnitude of the changes needed to minimize the loss.
Optimization algorithms like Stochastic Gradient Descent (SGD) or more advanced techniques such as Adam are commonly used for this purpose.
7. Training
We repeat the process of forward propagation, loss calculation, backpropagation, and weight updates for multiple epochs. During training, the neural network learns to recognize patterns and features that differentiate circles, squares, and triangles.
8. Evaluation
After training, we evaluate the neural network’s performance on a separate test set. We feed the test images through the network, and the predicted class is compared with the true labels to measure accuracy or other relevant metrics.
9. Prediction
Once the neural network is trained and evaluated, we can utilize it to make predictions on new, unseen shape images. The network takes in the image as input, performs forward propagation, and outputs the predicted probabilities for each shape class. The class with the most probability can be considered the predicted shape for the input image.
By training on a diverse dataset and optimizing the network’s architecture and training parameters, the neural network can learn to differentiate between circles, squares, and triangles based on the patterns and features it discovers during training.
Types of neural networks
Several types of neural networks are designed to address specific types of problems and data structures. Here are some commonly used types of neural networks:
Perceptron
Perceptron is one of the simplest types of neural networks. It consists of a single layer of neurons, known as perceptrons or artificial neurons. Each perceptron takes multiple inputs, applies weights to those inputs, sums them up, and applies an activation function to produce an output. The output is typically binary, indicating a class or decision.

Feedforward Neural Networks (FNN)
A feedforward neural network is composed of multiple layers of artificial neurons. It comprises an input layer, one or more hidden layers, and an output layer. An input layer transmits information to a hidden layer, which in turn transmits information to an output layer, facilitating a one-way flow of information. Each neuron in the network receives inputs, applies weights and biases, passes the weighted sum through an activation function, and forwards the result to the next layer.
FNNs are primarily used for classification, regression, and pattern recognition tasks.

Recurrent Neural Networks (RNN)
RNNs are designed to process sequential data, where the order and context of data points matter. They introduce feedback connections, allowing information to flow in cycles or loops within the network. RNNs have a memory component that enables them to retain and utilize information from previous steps in the sequence.
They are widely used for tasks such as natural language processing, speech recognition and time series analysis.

Long Short-term Memory (LSTM) networks
As a type of RNN, LSTM introduces memory cells to address the vanishing gradient problem. These memory cells allow for better retention and utilization of information over long sequences. They incorporate three gates (input, forget, and output gates) to restrain the flow of information and selectively update or forget information from the memory cell.
LSTM networks are particularly effective in tasks involving long-term dependencies, such as language modeling and machine translation.
Convolutional Neural Networks (CNN)
CNNs are primarily used for analyzing visual data, such as images or video, but they can also be applied to other grid-like data. They employ specialized layers, such as convolutional layers and pooling layers, to efficiently process spatially structured data. A convolutional layer applies a set of learnable filters to the input, performing convolutions to detect local patterns and spatial relationships. The pooling layers, on the other hand, reduce the dimensionality of the feature maps.
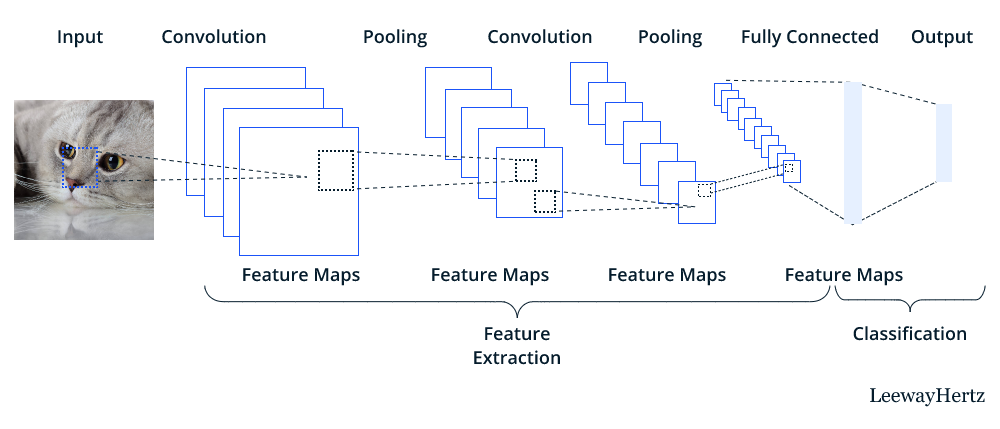
CNNs are known for their ability to automatically extract meaningful features from images, making them suitable for tasks like object recognition, image classification, and computer vision.
Modular neural networks
A modular neural network, also known as modular neural architecture, is a type of neural network structure that is composed of distinct and relatively independent modules. Each module is responsible for handling a specific subtask or aspect of the overall problem. The idea behind modular neural networks is to break down a complicated problem into simpler sub-problems and have specialized modules tackle each.
In a modular neural network, these modules often work in parallel or in a hierarchical manner, where the outputs of one module feed into another. This allows for greater modularity, flexibility, and easier debugging.
Launch your project with LeewayHertz
We build robust AI-powered solutions tailored to your needs
How to build and train a neural network?
Building and training a neural network may vary according to the type of neural network being built. However, as a starting point, let’s learn how to build and train a simple neural network.
Import the required libraries
First, we need to import all the prerequisites, including Torch and Matpotlib.
import torch from torchvision import datasets import matplotlib.pyplot as plt
Download and preprocess the data set
Next, download the intended dataset. Here, we will use the MNIST dataset, a popular dataset of handwritten digits.
mnist = datasets.MNIST('./data', download=True)
threes = mnist.data[(mnist.targets == 3)]/255.0
sevens = mnist.data[(mnist.targets == 7)]/255.0
len(threes), len(sevens)
Check the indexed images
Run the following code to visualize and inspect individual images from the MNIST dataset, specifically those corresponding to digit 3 and digit 7.
def show_image(img): plt.imshow(img, cmap='gray')plt.xticks([]) plt.yticks([]) plt.show() show_image(threes[3]) show_image(sevens[8])
Check the tensor size
Understanding the shapes of the tensors is crucial for further processing or analysis of the data. Use the following command to inspect and display the shapes of the threes and sevens tensors.
print(threes.shape, sevens.shape)
Merge the Dataset
Now, merge the threes and sevens tensors into a single tensor, combined_data, which contains the combined dataset. This helps create a unified dataset for further processing or analysis.
combined_data = torch.cat([threes, sevens]) print(combined_data.shape)
Flatten the images
Flattening refers to converting the 2D image representations into a 1D vector by concatenating all the pixels in each image. It is a necessary step for the neural network to take pixels as inputs and process them to give the correct output.
flat_imgs = combined_data.view((-1, 28*28)) print(flat_imgs.shape)
Define the target labels for the dataset
target = torch.tensor([1] * len(threes) + [2] * len(sevens)) target.shape
Create the neural network
Define reusable functions for the sigmoid activation function and a simple neural network. This provides building blocks for constructing and using neural networks.
def sigmoid(x): return 1 / (1 + torch.exp(-x)) def simple_nn(data, weights, bias): return sigmoid((data @ weights) + bias)
Initialize weights and biases
Next, initialize the neural network’s parameters (weights and biases). Proper initialization of weights and biases is crucial for the effective learning and convergence of the network during training.
w = torch.randn((flat_imgs.shape[1], 1), requires_grad=True) b = torch.randn((1, 1), requires_grad=True)
Define a loss function
Run the following set of codes to define an error function that measures the discrepancy between the predicted output (pred) and the target output (target).
def error(pred, target): return ((pred - target) ** 2).mean()
Train the neural network
Next, let us train the neural network using a simple gradient descent optimization algorithm.
learning_rate = 0.001
for i in range(6):
pred = simple_nn(flat_imgs, w, b)
loss = error(pred, target.unsqueeze(1))
loss.backward()
with torch.no_grad():
w -= learning_rate * w.grad
b -= learning_rate * b.grad
w.grad.zero_()
b.grad.zero_()
print("Loss:", loss.item())Launch your project with LeewayHertz
We build robust AI-powered solutions tailored to your needs
How to assess the performance of a neural network?
The performance of neural networks is assessed using several model evaluation metrics. Here are some commonly used metrics:
- Accuracy: Accuracy measures the proportion of correctly classified instances from the total number of instances in the dataset. It is a simple and intuitive metric, but it may not be suitable for imbalanced datasets where the classes are not equally represented.
- Precision: Precision measures the proportion of correctly predicted positive instances out of all positive ones. It focuses on the accuracy of positive predictions and helps evaluate the model’s ability to avoid false positives.
- Recall: Recall, also referred to as sensitivity or the true positive rate, quantifies the proportion of accurately predicted positive instances out of the total number of actual positive instances. It focuses on the model’s ability to identify all positive instances and avoid false negatives.
- F1 Score: The F1 score is the harmonic mean of precision and recall. It provides a balanced evaluation metric that considers both precision and recall. It is specifically beneficial when there is an imbalance between positive and negative instances.
- ROC Curve: The Receiver Operating Characteristic (ROC) curve offers a visual representation of the connection between the true positive rate (TPR) and the false positive rate (FPR) across various classification thresholds. By illustrating the trade-off between sensitivity (the ability to identify positives correctly) and specificity (the ability to identify negatives correctly), the ROC curve aids in determining an optimal threshold for classification.
- Area Under the ROC Curve (AUC-ROC): The AUC-ROC is another metric that quantifies the overall performance of a binary classification model. It represents the probability that a randomly chosen positive instance will be ranked higher than a randomly chosen negative instance. A higher AUC-ROC value indicates better model performance.
- Mean Squared Error (MSE): MSE is a commonly used loss function for regression tasks. It measures the average squared difference between the predicted and actual values. Lower MSE values indicate better model performance.
- Mean Absolute Error (MAE): MAE is another loss function for regression tasks. It measures the average absolute difference between the predicted and actual values. MAE provides a more interpretable metric than MSE, as squared differences do not influence it.
- R-squared (R2) Score: The R-squared score quantifies the fraction of the target variable’s variance that the input variables can explain. It operates as an indicator of how well the model fits the data. A value of 1 signifies a perfect fit, whereas a value of 0 suggests that the model fails to capture any information from the input.
When evaluating a neural network model, it is vital to consider the specific requirements of the task at hand and choose the appropriate evaluation metrics accordingly. The selection of metrics should align with the objectives and priorities of the problem domain.
Neural network vs. deep learning
Although neural networks and deep learning share similar concepts, they have distinct meanings in artificial intelligence.
Neural networks
Neural networks are a class of algorithms inspired by the structure and functioning of biological neural networks, such as the human brain. They are mathematical models composed of interconnected artificial neurons organized in layers. These networks can learn and adapt by adjusting the strengths (weights) of connections between neurons based on input data. Neural networks can be used for multiple tasks, including pattern recognition, classification, regression, and more. The term “neural network” is a general term that encompasses various network architectures and learning algorithms.
Deep learning
Conversely, deep learning is a subfield of machine learning that focuses on training deep neural networks. Deep learning models are characterized by having multiple hidden layers (referred to as deep neural networks) between the input and output layers. These deep neural networks can learn hierarchical representations of data by automatically discovering intricate features and patterns at different levels of abstraction. Deep learning models excel at learning from large and complex datasets, and they have achieved remarkable success in various AI tasks, such as computer vision, natural language processing, speech recognition, and more.
In essence, deep learning is an advanced approach to machine learning that leverages deep neural networks with multiple layers to extract and learn complex representations from data. Neural networks, on the other hand, are the foundation of deep learning models but can also refer to shallower network architectures or simpler learning algorithms that predate the deep learning era.
To summarize, neural networks are a broad class of algorithms inspired by the brain, while deep learning is a specific area of machine learning that focuses on training deep neural networks with multiple layers to learn hierarchical representations of data. Deep learning is a powerful technique within the broader context of neural networks, enabling the development of highly advanced AI models.
Practical applications of neural network
Neural networks have practical applications across various domains thanks to their ability to learn from data and make intelligent predictions. Here are some practical applications of neural networks:
1. Computer vision:
-
- Image classification: Neural networks can classify images into different categories, enabling applications like object recognition, autonomous vehicles, and medical image analysis.
- Object detection: It can identify and locate multiple objects within an image, enabling tasks like video surveillance, self-driving cars, and augmented reality.
- Image generation: Neural networks can generate realistic images, leading to applications like image synthesis, artistic style transfer, and deepfake technology.
2. Natural Language Processing (NLP):
-
- Sentiment analysis: Neural networks can analyze and classify the sentiment (positive, negative, neutral) expressed in text, resulting in applications like social media monitoring, customer feedback analysis, and opinion mining.
- Machine translation: Neural networks make it possible to handle machine translation tasks, facilitating text translation between different languages.
- Text generation: Neural networks can generate human-like text, enabling applications like chatbots, language modeling, and content creation.
3. Speech and audio processing:
-
- Speech recognition: Neural networks are used to convert spoken language into written text, resulting in applications like voice assistants, transcription services, and voice-controlled systems.
- Speaker identification: Neural networks can identify individuals based on their unique voice characteristics, enabling applications like speaker verification and access control systems.
- Music generation: Neural networks can generate original music compositions, aiding creative endeavors and generating personalized soundtracks.
4. Recommender systems:
-
- Personalized recommendations: Neural networks can learn user preferences and make personalized recommendations for products, movies, music, and more, improving user experience and engagement on platforms like e-commerce websites, streaming services, and social media platforms.
5. Financial applications:
-
- Stock market prediction: Neural networks can analyze historical financial data and make predictions about stock market trends, aiding in investment decision-making.
- Fraud detection: Neural networks can detect patterns of fraudulent activities in financial transactions, helping to prevent financial fraud and ensure security.
6. Healthcare:
-
- Disease diagnosis: Neural networks can analyze medical images, such as X-rays and MRIs to assist in diagnosing diseases like cancer, eye conditions, and neurological disorders.
- Drug discovery: Neural networks can analyze vast amounts of chemical and biological data to aid in discovering and developing new drugs and therapies.
- Health monitoring: Neural networks can analyze sensor data from wearable devices to monitor vital signs, detect anomalies, and provide personalized health recommendations.
In addition to these examples, neural networks have a number of practical applications. They have broad applicability across industries and continue to advance AI capabilities in areas where pattern recognition, prediction, and decision-making from complex data are crucial.
Real-world case studies of neural networks
Here are some real-world case studies that showcase the practical applications of neural networks:
Case study 1: ImageNet large-scale visual recognition challenge
- Category: Image classification using CNNs
- Description: The ImageNet challenge involves classifying images into one of thousands of categories. CNNs, particularly deep architectures like ResNet, have achieved remarkable accuracy in image classification. These networks learn to extract features from images and hierarchically classify them automatically.
- Impact: CNNs are widely used for tasks like object detection, facial recognition, medical image analysis, and even in self-driving cars for identifying pedestrians and road signs.
Case study 2: Google neural machine translation
- Category: Language translation with sequence-to-sequence models
- Description: Sequence-to-sequence models, often powered by recurrent or transformer networks, have significantly impacted language translation. Google’s translation services employ neural networks to translate text between various languages. These models capture contextual relationships between words and phrases, leading to more fluent translations.
- Impact: Neural machine translation has significantly improved the quality of automated language translation, making cross-language communication more accessible.
Case study 3: Automatic speech recognition systems
- Category: Speech recognition with RNNs
- Description: RNNs and their variations, such as Long Short-Term Memory (LSTM) networks, are used for converting spoken language into written text. These networks process audio inputs over time, capturing temporal patterns in speech.
- Impact: Applications include voice assistants like Siri and Google Assistant, transcription services, and accessibility tools for individuals with hearing impairments.
Case study 4: Detecting diabetic retinopathy
- Category: Healthcare diagnosis with deep learning
- Description: Deep learning models, including CNNs, have been used to analyze medical images for various conditions. For instance, CNNs can identify signs of diabetic retinopathy in retinal images, assisting in early diagnosis and treatment of the disease.
- Impact: Such models enhance the accuracy of medical diagnoses, potentially saving lives and reducing human error.
Case study 5: Self-driving cars
- Category: Autonomous vehicles with neural networks
- Description: Neural networks, including CNNs and LSTMs, enable autonomous vehicles to perceive and navigate their environment. These networks process sensor data such as images, LiDAR, and radar to make real-time decisions.
- Impact: Self-driving car technology has the potential to transform transportation, improving safety and efficiency on the roads.
Case study 6: Netflix movie recommendations
- Category: Recommendation systems with collaborative filtering
- Description: Neural networks can be applied to collaborative filtering, a technique that predicts a user’s preferences based on similar users’ preferences. This enables platforms like Netflix to suggest movies and shows tailored to individual viewers.
- Impact: Enhanced user experiences, increased user engagement, and improved content discovery on streaming platforms.
These case studies demonstrate the versatility of neural networks across various domains, from image analysis and natural language processing to healthcare and transportation.
Endnote
As we navigate the intricate landscape of neural networks, it becomes evident that they have transformed how we interact with technology. From computer vision to natural language understanding, neural networks have pushed the boundaries of what is possible, paving the way for unprecedented achievements. The evolving field of neural networks promises a future where intelligent systems continue to learn and adapt to enhance our lives in ways we never imagined.
Want to leverage the power of neural networks? Our team of experts specializes in developing customized neural network-powered AI solutions tailored to your specific needs. Contact us today!
Author’s Bio


Akash's ability to build enterprise-grade technology solutions has garnered the trust of over 30 Fortune 500 companies, including Siemens, 3M, P&G, and Hershey's. Akash is an early adopter of new technology, a passionate technology enthusiast, and an investor in AI and IoT startups.
Related Services

AI Development
Transform ideas into market-leading innovations with our AI services. Partner with us for a smarter, future-ready business.
Explore ServiceStart a conversation by filling the form
Once you let us know your requirement, our technical expert will schedule a call and discuss your idea in detail post sign of an NDA.
All information will be kept confidential.
Related Insights
Generative AI in High-Tech Manufacturing: Operating Model, Use Cases, Governance, and Future Trends
In high-tech manufacturing environments, generative and agentic AI can interpret, synthesize, and generate structured outputs from technical and operational information.

Comparison of Large Language Models (LLMs): A detailed analysis
Large Language Models (LLMs) have emerged as a cornerstone in the advancement of artificial intelligence, transforming our interaction with technology and our ability to process and generate human language.

Actionable AI: An evolution from Large Language Models to Large Action Models
Actionable AI not only analyzes data but also uses those insights to drive specific, automated actions.

Federated learning: Unlocking the potential of secure, distributed AI
Federated learning aims to train a unified model using data from multiple sources without the need to exchange the data itself.

Optimize to actualize: The impact of hyperparameter tuning on AI
Hyperparameter tuning is a critical aspect of machine learning, involving configuration variables that significantly influence the training process of a model.

Journey to AGI: Exploring the next frontier in artificial intelligence
Artificial General Intelligence represents a significant leap in the evolution of artificial intelligence, characterized by capabilities that closely mirror the intricacies of human intelligence.

How attention mechanism’s selective focus fuels breakthroughs in AI
The attention mechanism significantly enhances the model’s capability to understand, process, and predict from sequence data, especially when dealing with long, complex sequences.

What is LLMOps? Exploring the fundamentals and significance of large language model operations
LLMOps, or Large Language Model Operations, encompass the practices, techniques, and tools used to deploy, monitor, and maintain LLMs effectively.

Ensuring ML model accuracy and adaptability through model validation techniques
As businesses lean heavily on data-driven decisions, it’s not an exaggeration to say that a company’s success may very well hinge on the strength of its model validation techniques.




